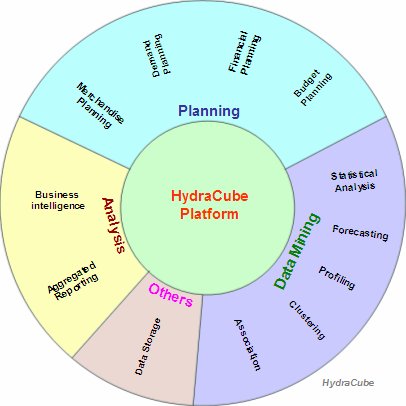
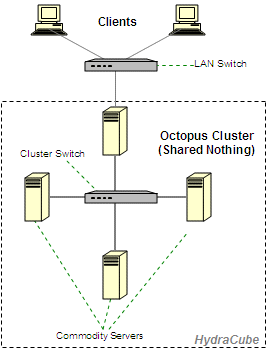
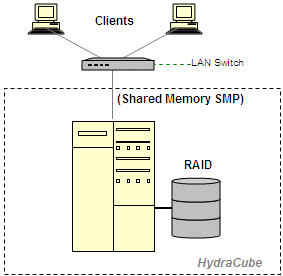
|
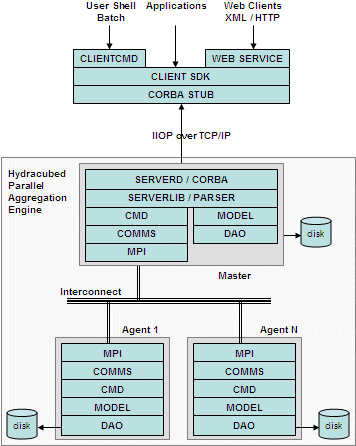
HydraCube Architecture Diagram
hydracubed is the parallel daemon software which runs
across multiple shared nothing desktop servers (or on SMPs) and
execute the commands.
Interconnect can be normal 100mbps
ethernet, Gigabit or Myrinet for better performance and lower
latency.
MPI is the messaging middleware and we
use MPICH
which is free from ANL. Current version of MPICH is not thread
safe for concurrent execution (send / receive). We employ a comms
framework to overcome this issue and also to provide us with a
higher programming abstraction.
CMD layer has the commands which are
remotely executed on every node and created and send by the
master process. It works along with comms layer to
achieve this.
MODEL layer has all the hierarchy & cube management
code along with OLAP query logic. It does all business
validations and computations. It runs on every node.
DAO is an abstraction over BerkeleyDB
and help us in persistence of hierarchy, cube and data
chunks.
SereverLib/Parser layer has the controller logic and the
MDX parser and runs in master.
serverd/CORBA layer is the CORBA interface for clients to
connect. Since it supports IIOP protocol any client (either C++
or java) can connect to the server. We use OmniORB
for CORBA support.
CORBA STUB is the client stub in C++ which client
SDK can use.
client SDK is in C++ and can be written
in java without much effort.
ClientCMD is the client command line
utility to execute HydraCube commands and queries. It is an
interactive batch utility which accepts commands and queries,
get it executed in server and display the result.
Web Service is the future implementation
possibility and will be using client SDK to interact with
server.
|